

After an uncertain landing a few hours ago (the airport in Madrid was barely working due to a snowy morning), I’ve just arrived home but instead of having some rest after an intense and though-provoking FOSDEM I felt the urge to start writing about my weekend in Brussels.
I’ve been there not only to enjoy this wonderful city with its trappist beers and great food, but specially to attend FOSDEM as I intend to do every year.

For those of you who don’t know FOSDEM, it’s the biggest conference in Europe (and one of the biggest around the world) related to Open Source development. It’s a huge event with hundreds of talks, workshops, gatherings and stands from all the relevant projects and communities in the FOSS (Free and Open Source Software) ecosystem. It’s also a marvelous place to do networking, because there are not only representatives of those projects but normally also the technical leaders of them. If you are good with faces (or with voices, like @lekum!) you can meet and greet a lot of important and interesting people.
I already wrote about it a couple of years ago, when I even gave a lightning talk in one FOSDEM Fringe event the Floss Community Metrics Meeting (FCM2).
The numbers of this year speak for themselves:
- more than 8,000 attendees in only two days
- 652 speakers in 690 different events (talks or workshops, mainly)
- 57 tracks in 33 different rooms
- more than 350 hours of content, almost all of the events are available online with live streaming during the conference
- 56 stands of all kinds of projects: FSFE, Python Software Foundation, the Apache Software Foundation, OSI, the Eclipse Foundation, O’Reilly, Fedora, OpenSUSE, Debian KDE, Gnome, LibreOffice, VLC, Jenkins, Perl, …
To make it more impressive, take into account that FOSDEM is organized by volunteers, everything is community driven and it’s free to attend. You don’t even need to register beforehand.

As usual, let me summarize some of the talks that I attended:
Talks
Consensus as a Service, Twenty Years of OSI Stewardship, by Simon Phipps and Italo Vignoli
The Open Source label was born in February 3rd 1998, so we celebrated its 20th Anniversary during the opening day of FOSDEM 2018. Simon (President of the OSI) summarized the evolution of the Open Source environment in the last two decades, also guessing what are going to be the main challenges for the Free Open Source Software for it’s third decade.
He remarked that Open Source (OS) projects should not have a business model, the companies that uses those OS projects are the ones that need a realistic business model. I totally agree with this, OS projects can be relevant and positive for the society in a lot more ways than profitability of the founders. Open Source allows software users and developers to advance in their software freedom at work as well as in private.
He labeled the first decade (1998-2008) the decade of Advocacy & Controversy. We all still remember when in 2001 Steve Ballmer as CEO of Microsoft said “Linux is a cancer” (although now apparently he loves it), or in 2005 when UNIX was made Open Source, or 2007 when Java was also made Open Source. In the beginning most OS was a proprietary replacement, but at the end of the decade everyone understood OS as a benefit.
Simon labeled the second decade (2008-2018) the decade of Adoption and Ascendancy, with three main aspects: broad enterprise adoption, problems with software patents and GPL enforcement. Since 2008 most hidden infrastructure is based in OS, since 2011 OS enabled the web service business era, since 2013 the OS is powering the cloud/containers revolution, … to the point that nowadays we can realize that Open Source is at the heart of most new software.
Simon quoted Eben Moglen and his “Licenses are Constitutions for Communities”, and explained that “Open Source licenses are the multilateral consensus of the permissions and norms for a Community”. That’s why it’s important to respect the licenses, and that explains why for the community any violation of the license it’s felt like an awful aggression.
Derived from the four essential freedoms of Free Software, Simon emphasized the real value of Open Source:
- Innovate without needing to ask first
- Start where others reached
- Stay in control of your own resources
- Share upkeep of your innovation
- Influence global ecosystems
- Be protected from others doing the same
Maybe my favorite talk this year. Don’t expect summaries as long as this one for other talks :-P
Cypher for Apache Spark (CAPS), by Martin Junghanns and Max Kießling
As part of Neo4J, the speakers explained why and how they created Cypher for Apache Spark (CAPS), to provide graph-powered data integration and graph analytical query workloads within the Apache Spark ecosystem. They presented the internal architecture, made a live demo with Spark and Apache Zeppelin and explained that CAPS is released as Open Source inside OpenCypher.
The Computer Science behind a modern distributed data store, by Michael Hackstein (@mchacki)
The first thing that Michael Hackstein (ArangoDB) explained was that he was replacing the original speaker (Max Neunhoeffer, that couldn’t attend for personal reasons), but in the end he gave a great talk about a complex topic, being clear and precise. Anyone could notice that the substitute speaker knew the subject perfectly.
Michael explained the main challenges when building or using a modern distributed data store. He started with an important advice: “The first law of distributed data is… don’t distribute data” :-) Having said that, he clarified that sometimes you cannot avoid it because you need to scale and/or you need to be resilient.
In a distributed system different parts need to agree on things (consensus) but it’s not always easy because the network has outages, drops, delays or duplicates packages, any disk fails or even an entire rack fails. He explained the basics of Consensus, as explained originally in the Paxos Consensus Protocol (1998) and later in Raft.
Another important thought was related to sorting. Most published algorithms are nowadays poorly efficient because the problem is no longer the comparison computations but the data movement between data stores. He explained Log Structure Merge Trees (LSM-trees) as a possible solution.
He also summarized other problems like the synchronization of machines (mitigated with Hybrid Logical Clocks) and Distributed ACID transactions, only supported as off today by Google Spanner (because they have the money to use atomic clocks) and Cockroach DB an Open Source clone of Spanner that achieved it without atomic clocks.

Digital Archaeology, Maintaining our digital heritage, by Steven Goodwin (@MarquisdeGeek)
Steven Goodwin is the founder of the Digital Heritage, a (let me quote) “plan to collate the learnings and knowledge of computer systems from 1975 onwards so that students of technology and scholars of the future can understand how they work, how to use them, and how they affected the culture of the 20th century”.
He explained how in a few years time it will be difficult or even impossible to study retro-computers given the fact that its software is either proprietary, closed-source, written in an obsolete programming language or protected to prevent copying. Not only this, the hardware is also failing, the magnetic devices are no longer storing the information and so on.
After raising awareness of the problem, he also gave several recommendations and methods necessary to preserve our legacy using emulations, mainly based in Open Source projects.
JVM startup: why it matters to the new world order, by Daniel Heidinga
In the old world order the deployments were infrequent so the startup time was a very small fraction of the total up time. Now in the new world with CI/CD systems, microservice or serverless architectures controlling the startup time is essential. This topic is very hot right now.
Daniel (OpenJ9 Project Lead) explained the problem and provided possible solutions inside the JVM, focusing mainly in the use of OpenJ9’s SharedClasses.

Class Metadata: A User Guide, by Andrew Dinn
Andrew Dinn (Red Hat Open JDK) explained clearly what is the Class Metadata and why it matters inside the JVM. He also gave some real-life use cases to explain how design decisions can incur or avoid Class Metadata costs.

Java in a World of Containers, by Mikael Vidstedt and Matthew Gilliard
Mikael (Director of the JVM group at Oracle) and Matthew (also from Oracle) explained that Oracle is focused on maintaining Java as the main language in the containers ecosystem thanks to, according to them, some of its characteristics:
- Managed language/runtime
- Hardware and operating system agnostic
- Safety and Security enforced by the JVM
- Reliable as compatibility is a key design goal
- Runtime adaptive
- Rich ecosystem
Also related to reducing the startup time and footprint needed, they also explained how (using the modular system of Java 9) creating custom JREs allows you to reduce the size of the JDK needed inside the Docker container. A full JDK weights around 568 MB, the java.base module just 46 MB and a reasonable set of modules with complete capabilities could be around 60 MB. It can be further optimized using jlink –compress but it’s a trade-off between size and compressing/uncompressing effort.
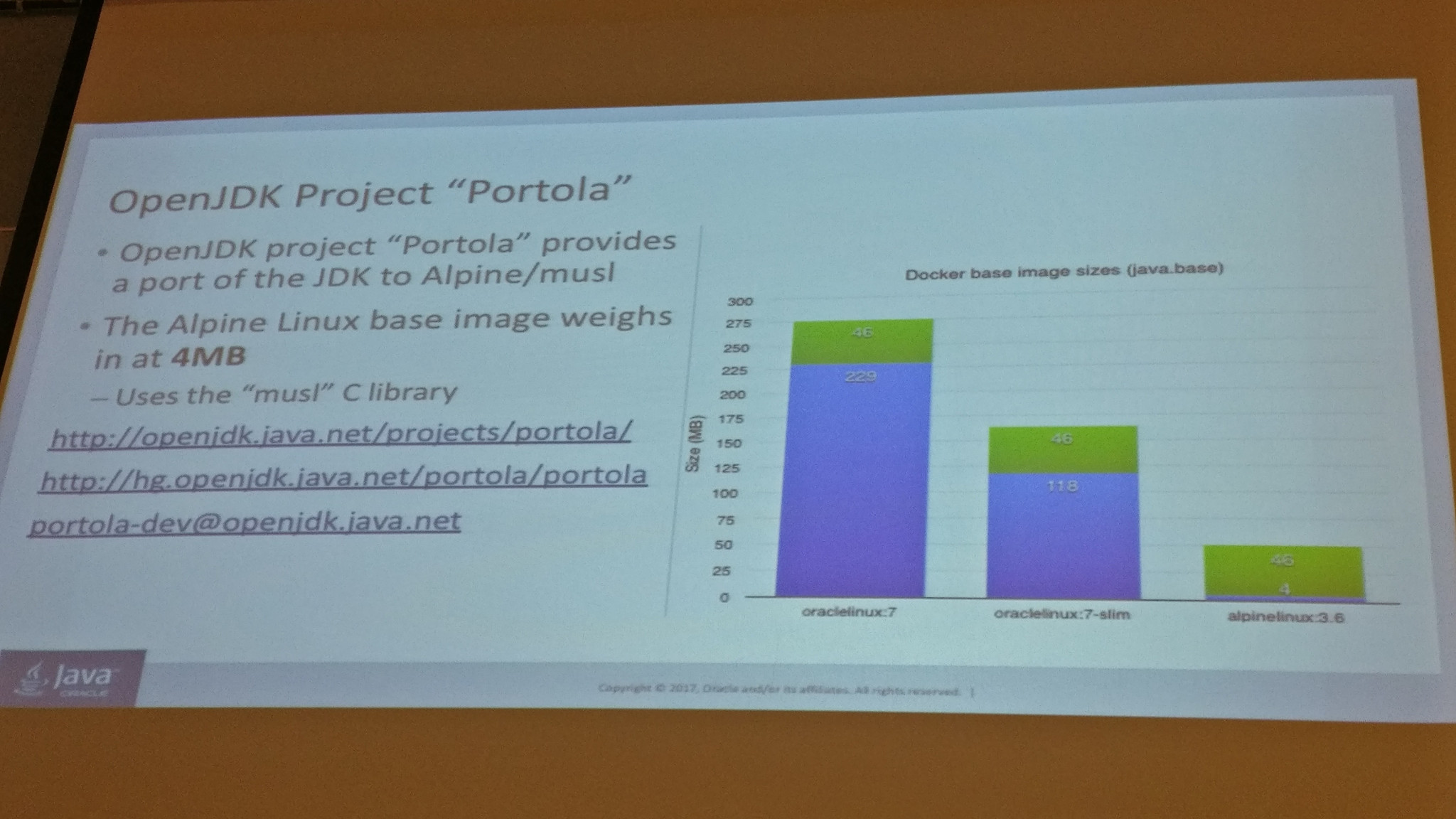
After reducing the JDK layer of a container, the next battle is in the operating system layer. They announced and presented OpenJDK Portola Project, a port of the JDK to use Alpine Linux (the base image weights just 4 MB) and the musl C library. Very impressive.
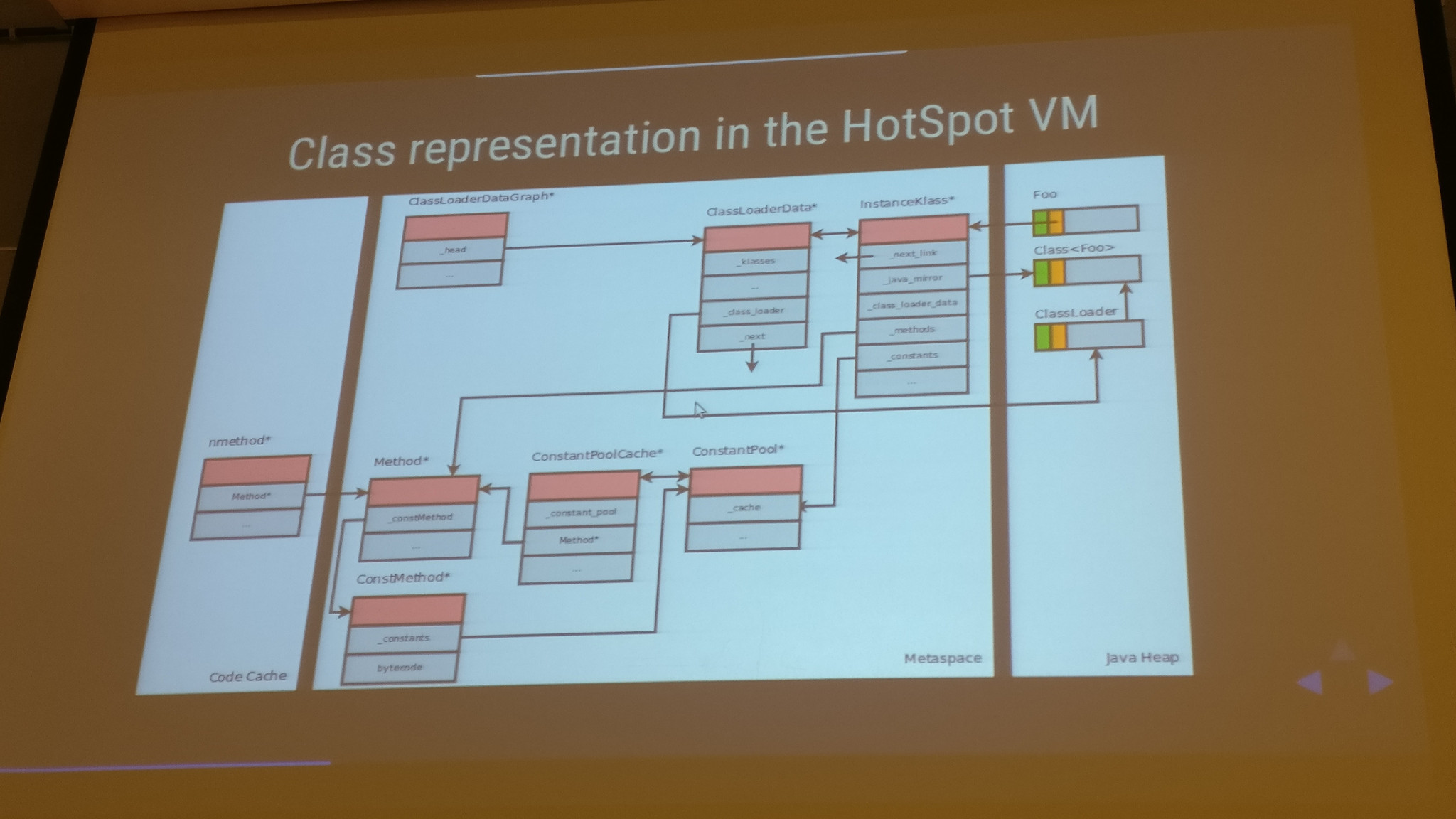
Class Data Sharing, Sharing Economy in the HotSpot VM, by Volker Simonis
Volker (SAP) introduced Class Data Sharing (CDS), explained clearly the implementation details and finally he demonstrated it’s advantages in some use cases.
Hairy Security, the many threats to a Java web app, by Romain Pelisse and Damien Plard
Romain (Red Hat) and Damien (Solaris Bank) gave a fun and instructive talk about security, challenging some myths.
They reminded us that it’s not a question of ‘if’ but ‘when’ you’ll be hacked.
If you want to read my summary of the next day you can follow this link: FOSDEM 2018: Sunday.




